
Compress Then Evict: Pushing Vector-Level Context Compression to 3x

Where we left off
In this series, we’ve been tackling a key problem plaguing coding agents, and broadly AI use; namely, models and agents face significant tradeoffs as their context windows grow. They lose details, get slower, and generally perform worse. Throughout the series, we’ve evolved our approach to use context more efficiently and reduce context size without losing key details that would diminish performance.

In our last entry, we found a compression recipe that works at the native representation layer where models operate.1 Our experimentation is operating at that level, where the model is actually doing the work. We optimized “virtual” tokens to match the model’s Value vectors, weighted the pooling by perplexity2, and interpolated positions to preserve attention routing. That recipe preserved all tested facts3 at 3.2x compression on individual turns, and 7–8 of 8 facts at 2x across a 10-turn sequential conversation, depending on the run.4
Two questions followed naturally: can we push beyond 2x sequential compression? And what’s the limit?5
This post covers both: a series of experiments that map where performance breaks down, and a combination of compression with KV-cache eviction that moves our best sequential result from 2x to 3x, while holding around 7–8 of the 8 tested facts.
For more information on testing methodology, the previous perplexity-weighted V-pooling recipe, definitions, the mechanisms behind everything, take a look at the above links.
Refresher: what we’re modifying and why
Broadly, the transformer architecture6 ubiquitous in modern LLMs contains two key components7: the attention step (gathering information, which tokens are relevant to each other), and the feed forward step (applying that gathered information).
The attention step scales roughly quadratically with sequence length, while the feed forward step grows linearly. During generation, KV cache grows linearly with context length, and each new token calculates attention over that growing cache, so long contexts put pressure on both memory and compute.
Last time, we focused on finding a recipe for vector compression that worked. This time, we’re combining that finding with KV cache eviction, or discarding the portions of the KV cache generated by the attention step that we don’t need.
The enhanced recipe
Neither compression nor eviction works well enough alone to preserve tested facts at a 3x final cache target8, and we started hitting the limits of our technique at 2x compression.
Pure compression at 3x scored about 5.3 out of 8 across seeds, since compressing every turn to that degree against an already-degraded cache blurs too many details.9 Pure eviction, keeping the top third of tokens by attention importance and dropping the rest, scored about 2 out of 8, because most of the critical content gets dropped entirely.
But what if we compress first, and then evict? KV cache eviction, dropping low-importance entries from the cache, is a well-researched technique that was a logical complement to our existing methodology.
The intuition behind this is that compression turns full deletion into something more graceful. Before eviction, each virtual token already carries a blended approximation of nearby original tokens. That means evicting one virtual token is less likely to erase exactly one unique original fact than evicting one raw token.
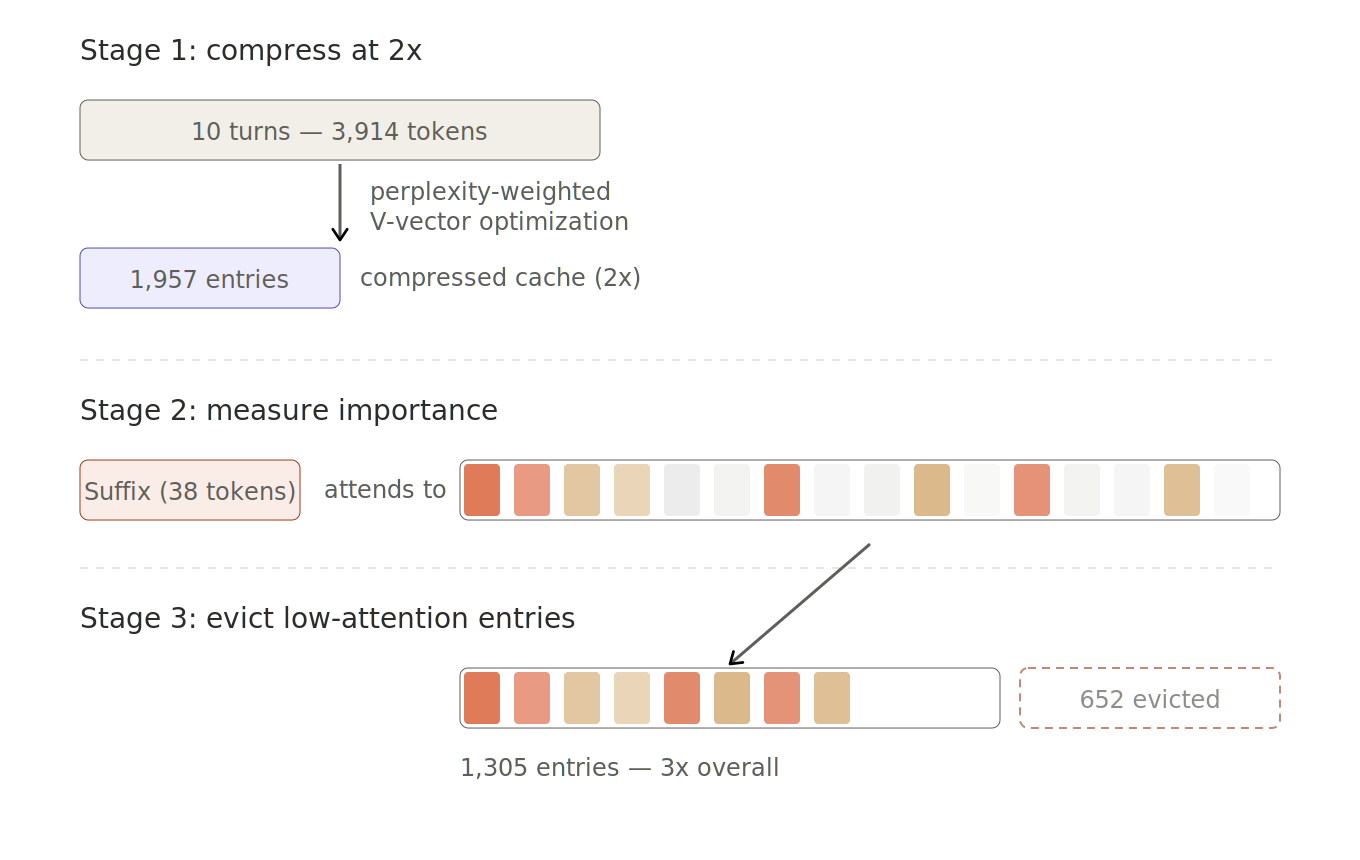
The pipeline is as follows:
Compress all 10 turns at 2x using our previous strongest recipe (~1,957 cache positions; ~7/8 across runs)
Measure how much the model attends to each compressed cache entry
Evict the least-attended entries to reach 3x overall (~1,305 positions)
The result, alongside the two approaches it combines: compress-then-evict at 3x held about 7.3 out of 8 facts across 3 seeds, including one run that recovered all 8. That is 50% more compression than our previous 2x result.

Compressing with no eviction is not lossless, even at low ratios. At 1.5x, it already drops one fact, holds around 7 out of 8 through 2x, then slides to 5.3 at 3x and 2.3 at 4x. What makes it useful is not that it keeps everything, but that it spreads each token’s information across the pooled virtual tokens, which is what lets eviction later strip out redundancy without dragging unique facts along with it.
Why this combination works
Compression and eviction have complementary failure modes. Pure compression at 3x degrades everything, because each token’s information is spread thinly across too few virtual tokens. While nothing is lost completely, everything is blurry—bcryptjs becomes bcrypt, and dev-secret becomes dev-dev-dev-dev.
On the other hand, pure eviction at 3x preserves some tokens perfectly but drops 67% of them entirely. The kept entries are exact, but critical context is gone with no trace.
Compress-then-evict gains from the strengths of both. After compression, every token’s information is approximately preserved in the cache and spread across virtual tokens through pooling. When we then evict the least-attended 33% of cache entries, the evicted information is likely partially captured by surviving virtual tokens that share pooling boundaries (though we haven’t verified this directly). It appears that eviction removes the least useful approximations rather than unique information.
There is, however, a simpler explanation to be ruled out first. Eviction keeps the tokens the model attends to most, so if the tested facts already live in those high-attention tokens, eviction would hold on to them on its own, whether or not I compressed them first. In such a scenario, a high score would then say nothing about what compression contributes.
The above heat map lets us check this directly—if the tested facts were concentrated in the tokens the model attends to most, eviction by itself would be enough to keep them. However, it doesn’t play out that way. Evicting down to a 3x cache with no compression holds only 2 of the 8 facts, while compressing at 2x first and then evicting to the same size holds ~7. At minimum, 6 of the 8 facts are not preserved by the high-attention raw-token subset alone. That makes it much more likely that the compression step is carrying useful information through, rather than eviction simply taking credit for facts it would have kept anyway.
Compression and eviction break on different facts, which is a useful check that the per-question breakdown is more than just due to averaging. The ones heavy compression destroys are the long, spread-out facts, like the full validation ruleset and the agent’s verification step, while moderate 2x compression keeps those intact.
Heavy eviction breaks a different fact: specifically, the structural question about what the markdown converter handles, which compression on its own preserves up to fairly high ratios. That failure mode lines up with the concern CodeComp (Chen et al., 2026) describes, since it argues attention-only importance discards structurally critical code tokens, which is a caveat for our attention-based eviction. Because the two methods fail on different questions, combining them at the 2x-plus-light-eviction point holds on to more of the set than either could alone.
The compression frontier
Rather than fix compression at 2x and only vary eviction, I wanted to map the full tradeoff between the two techniques. I ran an experiment with six compression ratios and three overall cache targets, repeated across three seeds to determine how much is run-to-run noise.
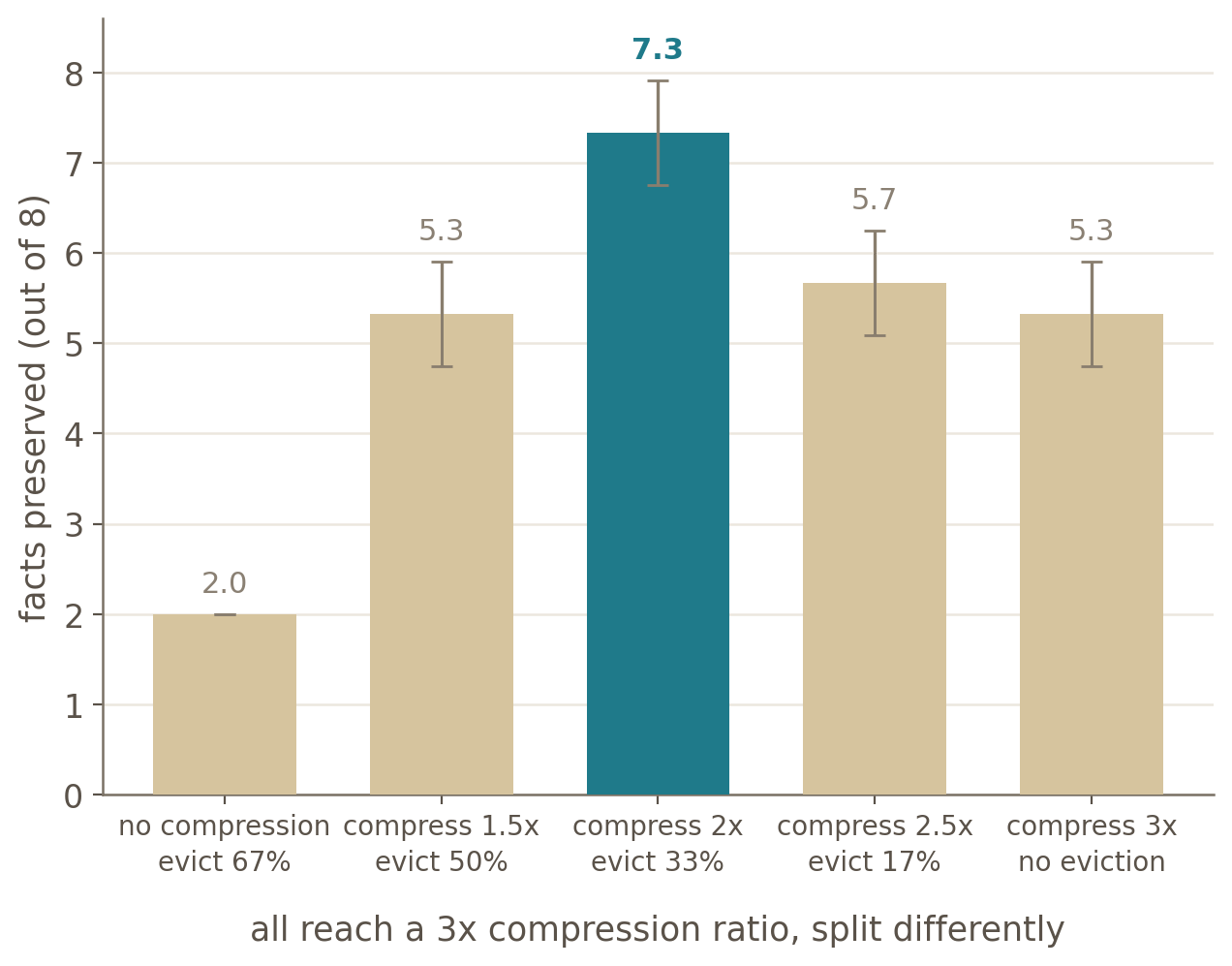
The clearest result is that at a fixed cache budget, how the work is divided between compression and eviction matters, and there seems to be an optimal split.
To reach a 3x compressed cache target, compressing at 2x and then evicting the rest scores ~7.3 out of 8 facts on average, while reaching the same 3x cache by compression alone gets ~5.3 and by eviction alone only ~2. The range of correct facts spans from 2 to ~7 depending purely on the approach, and moderate compression followed by eviction is the clear winner in this setup.
A surprising result was that locking compression to lower than 2x while using heavier eviction to hit the same final cache target does not help. Compressing at 1.5x and then evicting at a higher ratio to hit 3x falls back to around 5.3 correct facts, because the heavier eviction it forces is lossy. The 2x point wins because it seems to compress just enough to leave a usable safety net without blurring the content past recovery.
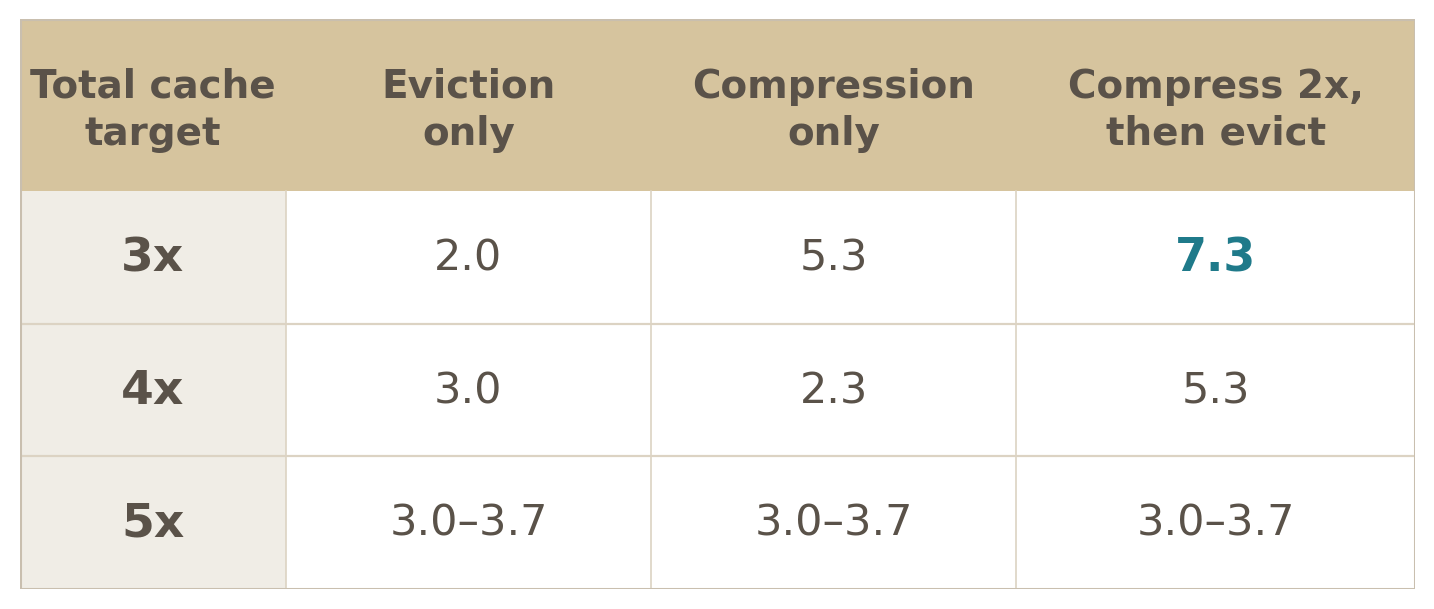
The same pattern of results hold at 4x total cache compression, though more weakly. By a 5x compression ratio, the information has degraded enough that the split stops mattering. Past a 3x cache, performance falls off no matter how the compression budget was allocated. Choosing this split adaptively per context, rather than by hand as I did, is the clear next step.
Finding the right eviction signal
We tested two attention signals to decide what to evict. Unlike our previous work in optimizing a mean-pooling target, attention is a natural first signal to test for cache eviction, because the model already computes which prior positions it uses during generation. It is not the same thing as semantic importance though, which is why the pure-eviction baseline fails on several facts. This also lines up with what Steele (2026) found, which is that attention measured during prefill10 carried about as much signal for importance as a far more complicated learned scorer did. That is reassuring for our decision to lean on attention over the uncompressed cache rather than trying to train something to predict importance.
The question then became what specific type of attention to use:
Pre-state attention (8/8 on the original single run, about 7.3 out of 8 once I seeded it): Measure attention on the original uncompressed tokens, then map those importance scores to the compressed virtual tokens.
Post-state attention (7/8, from a single run I have not re-seeded): Measure attention on the compressed virtual tokens directly. This is a “noisy” signal because the model is attending to approximations, so the attention pattern doesn’t fully reflect what the model would attend to on clean data.
There is, however, an important difference between the two. Measuring pre-state attention requires the full uncompressed KV cache to exist at measurement time. In our experiments, we computed attention from the final prompts over the entire raw cache, then transferred the scores to the virtual tokens. A production system that compresses each turn as it arrives never sees that raw cache, so pre-state attention is best understood as an “oracle.” The comparison is encouraging, because the signal a real system would have access to lands within about one question of this oracle. I would caution here not to lean too hard on that one-question gap, though, since both numbers carry the same seed-to-seed noise, and I only re-seeded the pre-state condition.
Matching the level of abstraction
Looking back across these experiments, the techniques that worked seem to share a characteristic. Each of them takes a signal that the model itself produces and applies it to a decision at the same level of abstraction that the signal lives at—specifically, whether the signal is calculated based on a representation, a token, or a position.
V-only optimization matches representations to representations.
Perplexity-weighted pooling takes the model’s per-token surprisal and uses it to weight per-token pooling.
Position interpolation maps the real RoPE positions onto the virtual ones.
Attention-based eviction uses the model’s own attention scores to decide which cache entries to drop.
In all of these, the signal and the decision sit at the same level, so there is no translation step in between for information to fall through.
The clearest failure went the other way. Code-pattern exemption ran a regex over English text to decide which KV entries to keep verbatim, which meant that a surface-text signal was driving a representation-level decision. It did manage to fix bcryptjs, since that got caught inside a require(’bcryptjs’) statement, but it broke Express and SQLite because those appear in prose. The signal was defined over the wrong kind of object.
Of course, other failures are messier than this idea alone would predict. V-uniqueness exemption actually did use an endogenous signal, namely, how distinct a token’s Value vector is from its neighbors. It appears to have used the wrong one, since the js in bcryptjs was not distinct enough to get protected.
Other failures, however, aren’t fully abstraction-level stories. Both exemption approaches also paid a budget tax, which I’ll return to below, and Part 4’s attention-weighted pooling failed for a different reason in that it’s query-specific. Weighting toward one question’s attention pattern blurs the tokens other questions need, so it’s overfitting to a single query rather than mismatching levels.
Keeping in mind the limitation of one transcript and a handful of experiments, it’s hard to claim that this is universal law. LLMLingua’s work is a useful boundary case here. It uses perplexity (a model signal) to drop text tokens and works well. I view that as mostly consistent with the heuristic rather than a contradiction, because both the signal and decision are defined per text token. Even as a heuristic rather than a law, matching abstraction layers is the first tool I would reach for when developing new techniques, because it’s the lens that makes the most sense of these results.
Connection to sparse attention architectures
This work and line of thinking reveals something interesting about attention itself—reaching 3x compression overall means the eviction step drops about a third of the post-compression cache entries while still holding around 7-8 of 8 facts, and a larger share (on the order of 40%) at 3.5x before performance falls off more steeply.
In other words, a meaningful fraction of the already-compressed cache draws little enough attention that the model barely “misses” it once it's gone. This is adjacent to the sparsity assumption that sparse attention architectures rely on: not every prior position needs to participate equally in every future attention computation.
MiniMax’s new MSA architecture in their M3 model, for example, pre-filters which KV blocks will receive meaningful attention and skips the rest entirely. Their self-reported benchmarks indicate that sparse attention matches full attention on the vast majority of capabilities. I see this as conceptually similar to Mixture of Experts11 applied to the attention step—MoE routes each token to a subset of FFN “experts,” skipping the rest. MSA is analogous at the attention level: it routes each query to a subset of KV blocks rather than attending densely over everything. Both avoid computing everything by cleverly routing to the relevant subset.
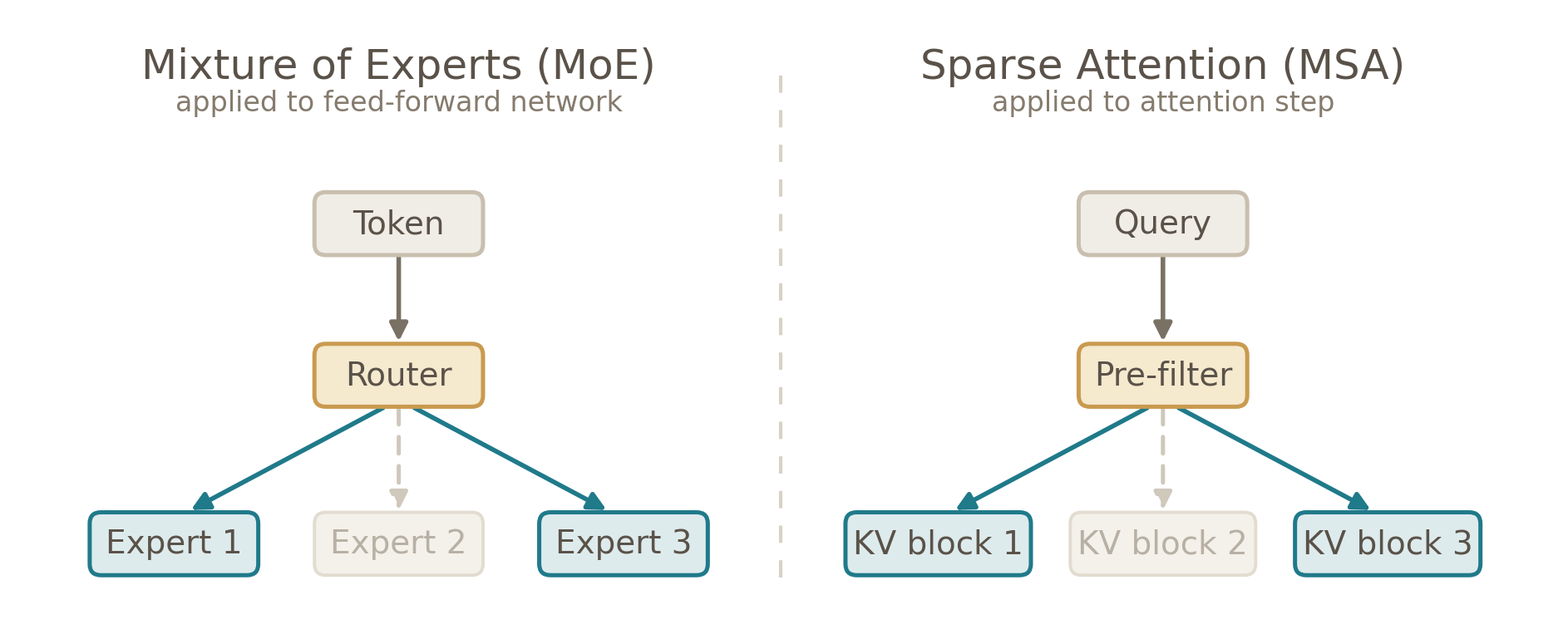
The two approaches address different cost dimensions. While sparse attention reduces compute per forward pass, since fewer attention scores get calculated, context compression reduces memory and improves signal-to-noise, since fewer entries compete for attention weight. In a sense, our eviction frontier provides one small application-side data point on how much redundancy may exist.
It’s worth noting that this idea did not start with M3; it comes out of a line of trainable sparse-attention work, with DeepSeek’s Native Sparse Attention as a well-known early example, and MiniMax Sparse Attention (MSA) and Mixture of Block Attention (MoBA) develop the line of thinking further. There is also recent work that studies compression tolerance directly as a way of measuring how sparse attention is12 (“Physics of KV Cache Compression”), which is close in spirit to what our eviction frontier is doing from the application side.
Dead ends and failed attempts
Adding Key vectors back pre-RoPE didn’t help
Our Part 4 recipe optimizes only Value vectors, circumventing the RoPE problem entirely.13 The obvious question that followed was what would happen if we brought Keys back. EliteKV takes the RoPE problem with Keys head-on, by working out which rotary frequencies each head relies on and then doing a small amount of uptraining, whereas we just circumvented the whole thing by never touching K at all.
RoPE rotations are deterministic and reversible, so we can undo the rotation, optimize K in the position-independent pre-RoPE space, then let the model re-apply RoPE at the correct positions during inference. Note that I was still optimizing the virtual-token inputs, but added a loss term for their pre-RoPE K projections alongside the V loss.
While the implementation worked, adding both K and V changed nothing at any ratio on any turn. The 4.8x failures from Part 4’s single-turn evaluation were identical, and on turn 18, the long single-turn test case from that same evaluation, K+V actually scored worse than V-only, because the K loss competed with the V loss for the optimizer’s limited budget.
The lesson here is that the compression bottleneck in our evaluation was the fidelity of content from V vectors, not the routing information in K vectors. If we think of K as an index of a library and V as the book, our V-only approach already gets the model to the right position and just finds a blurry book there. Extending this somewhat silly metaphor to its logical conclusion, a marginally better index doesn’t help make the blurry book any less blurry.
Cartridges (Eyuboglu et al., 2025) optimizes a compact KV cache by backpropagating into both K and V on documents. A separate group later did a mechanistic study of those caches (Diaz, 2025) and found that the keys end up behaving as stable routers while most of the compression comes from the value vectors. It is a different setup and method from ours, but they reached the same conclusion about where the content actually lives, which makes me less worried that the V-only result is purely an artifact of our particular transcript.
This makes architectural sense, because in RoPE-based architectures, position is applied to Q/K during inference, so avoiding direct optimization of already-rotated K vectors circumvents one major source of mismatch. In this setup, that seemed more important than trying to improve K fidelity directly.
Token-level exemption made things worse
The question I was answering with this attempt was: if some tokens are critical (bcryptjs, file paths, string literals), why not keep them verbatim and only compress the rest?
We tested two different exemption signals:
V-uniqueness
Signal: Tokens whose Value representations are most different from their neighbors.
Result: Fixed Q1 (preserved Express and SQLite) but broke Q4 (
bcryptjs→bcrypt—thejssuffix wasn’t unique enough to be exempted).
Code-aware pattern matching
Signal: Regex-based identification of file paths, require()/import package names, and short string literals.
Result: Fixed Q4 (caught
bcryptjsby matching it inside arequire('bcryptjs')statement) but broke Q1 (Express and SQLite appear in prose, not in code patterns) and Q3 (structural knowledge, not tied to any pattern).
Both times, exemption traded off one failure for another, and the cause was an underlying budget “tax.” Exempting 15% of tokens leaves less room for everything else, forcing the rest to compress at 2.4x instead of 2x, and that extra 0.4x is enough to push some facts over the edge. Uniform 2x compression with no exemption, by contrast, scored 8/8 in the same run.
It’s important to note here that we can only draw this specific conclusion in the confines of this experiment, though I still believe there’s potential in this broad methodology applied in other ways.
The path to productionization
One natural critique of our compression recipe is that per-instance gradient optimization takes several minutes per turn.14 How can we make this practical?
One constraint that’s important to note: everything here needs gradient and representation-level access to models, which means it’s deployable by whoever has access to model weights, and not by an application developer working through a closed API.
The amortized encoder
Productionizing what we’ve done would require building what’s often called an inference network or amortized encoder, a small neural network that predicts virtual token embeddings in a single forward pass, replacing the 300-step15 optimization loop.
The training pipeline would be:
Run per-instance optimization on thousands of diverse coding transcripts (our current technique).
Each run produces an
(original tokens, optimized virtual tokens)pair, creating supervised training data.Train a small transformer16 to predict the virtual token embeddings from the original token embeddings.
At inference time, run one forward pass through the encoder to create these virtual tokens, removing the need for expensive gradient descent at inference time.
This is the standard pattern for “amortizing” per-instance optimization. KV-Distill (Chari et al., 2025) trains this kind of single-pass compression adaptor with a student–teacher objective, and more recent work pushes the same amortization further. What follows is how I’d expect that pattern to work in our V-only, perplexity-weighted setting, along with the known failure modes.
The most important of these is the quality gap: amortized encoders typically don’t reach per-instance optimization quality. For our application, this means the no-measured-fact-loss threshold would likely drop from the 3.2x we saw on single turns to something lower. That’s still useful, and the gap narrows with more training data and better architectures.
The second is generalization: the encoder must work across different conversation types, not just memorize the training distribution. Coding conversations are diverse across languages, frameworks, and patterns, but they share structural similarities, like tool calls, file reads, and code blocks that an encoder can learn.
The third issue is that this type of solution is specific to particular models. An encoder trained for Qwen 7B probably won’t work for other providers’ models, because each model has its own internal representation space. In practice, this means model makers would train encoders for their own models, which follows the same pattern as the caching techniques being implemented by providers server-side.
What a production system looks like
Putting it together with the compression recipe, KV cache eviction, and prompt caching from Part 3:
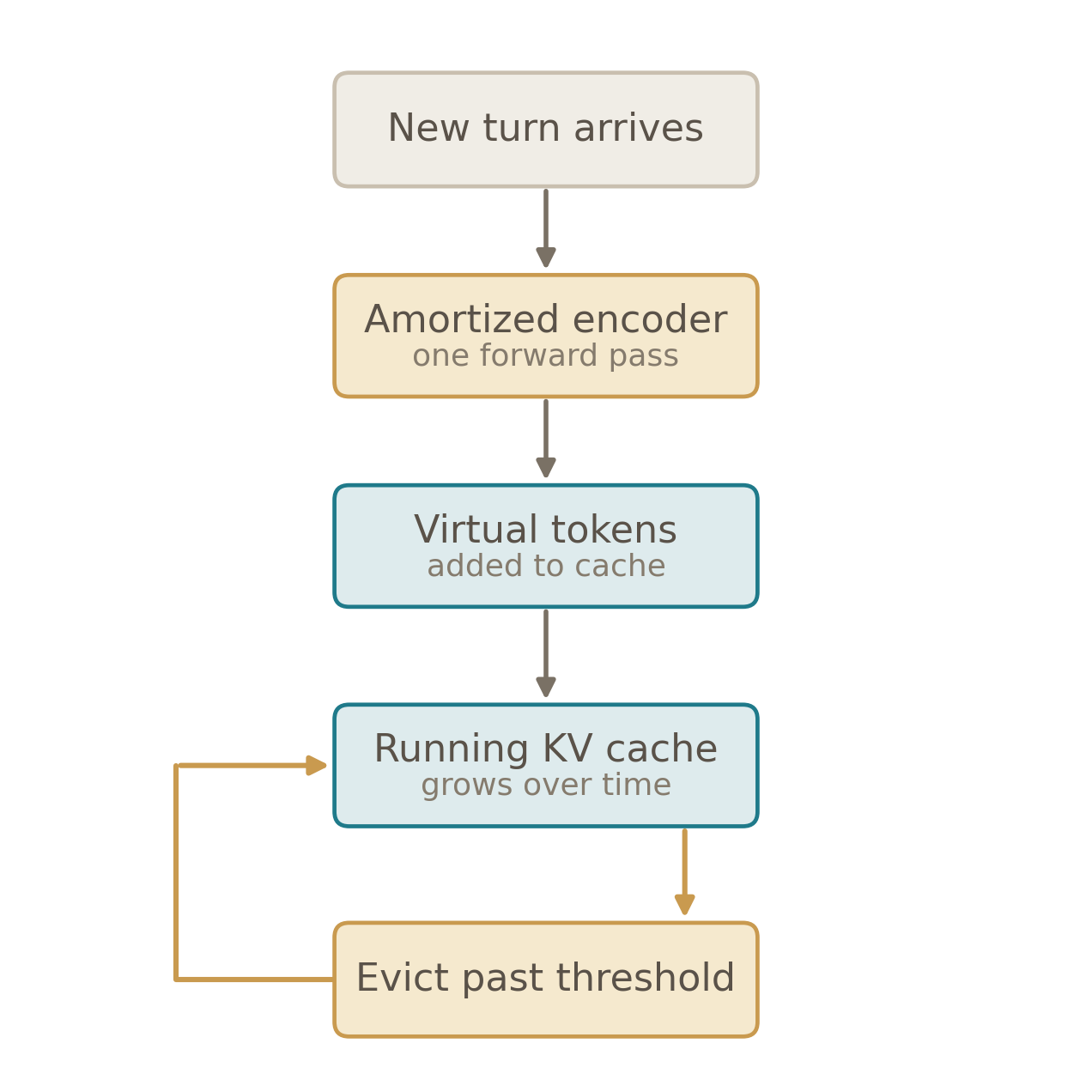
Here’s how it works: a turn arrives → the encoder compresses it to virtual tokens in one forward pass → virtual tokens added to the running KV cache → when cache grows past a threshold, we evict least-attended entries using attention scores from the most recent generation.
There are a few interesting product questions here around when to trigger eviction (fixed cache size vs. adaptive threshold), how aggressively to trim, and whether the threshold should vary based on task complexity. The primary reason to build the encoder comes down to latency. A 300-step gradient descent loop inserted at inference time would add minutes per turn and be untenable to users. An encoder would replace that with a single forward pass that could likely be run in tens to hundreds of milliseconds. Of course, where that processing is placed matters as well. Compressing turns only after responses are finished helps effectively hide the latency cost from users.
Note that the eviction signal here is the post-state one, since the raw cache never exists in this pipeline. In our eval, that costs about one question relative to the oracle signal.
Conceptually, this setup is compatible with prompt caching already done by model providers, because compressed turns are stable representations that can be reused. Implementation details would depend on the serving stack of course. The compressed prefix is shorter, so cache hits are cheaper and cache misses process fewer tokens. Compression reduces token count while caching reduces per-token compute cost.
The narrow product implication of this experiment17 is that context management likely should not use a single compaction mechanism. A realistic agent harness may need to choose between multiple treatments, including compress, preserve verbatim, evict, or externalize depending on the kind of information and how the model is using it.
Future work
Broaden evidence base: All conducted experiments used one transcript and one model. Testing across multiple codebases, programming languages, and model sizes would help generalize the explored techniques.
Retroactive attention tracking: Research suggests that predicting which tokens will be important is difficult18, due to a circular dependence between future queries and token importance. Rather than predict, we could track which cache entries the model actually attends to across multiple interactions, and build empirical importance scores over time. This circumvents the prediction problem by measuring what mattered rather than guessing what will.
Amortized encoder prototype: Train a small network on
(original, optimized virtual token)pairs to test the amortization gap empirically. This is the direct path to production.
Appendix
Limitations
Generalizability Caveat:
What this does not show: it does not show that 3x compression works generally, that attention is a sufficient importance signal, that the method improves real agent task success, or that an amortized encoder would match per-instance optimization.
What it does show is narrower: in this setup, compression and eviction had complementary failure modes, and the split between them mattered substantially at a fixed cache budget.
Model choice and scale: All of the experiments were conducted using Qwen 2.5 Coder 7B. Larger models with more attention heads and parameters might behave and perform differently. On one hand they might have higher representational capacity in each virtual token. On the other, there are more complex internal representations for a virtual token to approximate. We were hardware bound, but I’d love to test the same mechanisms in more capable models.
Eval / benchmark simplicity: We used a single transcript with a set of binary evaluation questions for simplicity. In earlier experiments, broken pipelines and things as mundane as computer sleep caused enough restarts that I leaned toward the simplest setup possible for this phase of research. Three seeds per condition were added to understand per-run variance and the impact of seeding. Because the same factual test questions guided much of this exploration, I treat them as development tests rather than a final evaluation. They are useful for understanding whether specific information survived compression, but they’re not sufficient to generalize. The compression threshold and degradation patterns need validation across different codebases, programming languages, and types of conversation before they can be trusted to hold in general.
Oracle Signal: The pre-state attention signal requires the full uncompressed cache at measurement time, which makes it impractical for production. On the original single run it scored 8/8, and about 7.3 out of 8 once I seeded it. The deployable post-state signal scored 7/8 on a single run, close enough that the gap sits inside the seed noise.
Relationship to existing work
Our main technique, embedding optimization (without pre-training), builds directly on Kuratov et al.’s work demonstrating that hundreds of tokens can be compressed into optimized embedding vectors (Cramming 1568 Tokens into a Single Vector, ACL 2025). We apply their technique to multi-turn coding agent conversations and add the V-only optimization target, perplexity-weighted pooling, and sequential turn-by-turn compression.
The KV cache compression research field is quite active. Most approaches compress the cache after computation through quantization or eviction. Our approach is different in that we optimize input embeddings beforehand. Notable work in this space includes EliteKV (RoPE frequency selection), CodeComp (structural compression for coding agents).
KV cache eviction methods like H2O and SnapKV manage growing context by dropping low-attention entries entirely. Our compress-then-evict result shows these are complementary to embedding compression, because compression preserves approximate information as a safety net, and eviction removes redundancy.
LLMLingua (Jiang et al., 2023) uses perplexity to discard tokens at the text level. We use perplexity to weight V-vector pooling at the embedding level—the same signal applied at a different level of the model.
Anthropic's guidance on session management and context rot informed our experimental motivation and how widespread this problem is.
Bibliography
Kuratov et al., “Cramming 1568 Tokens into a Single Vector and Back Again: Exploring the Limits of Embedding Space Capacity.” ACL 2025. https://arxiv.org/abs/2502.13063
Eyuboglu et al., “Cartridges: Lightweight and General-Purpose Long Context Representations via Self-Study.” 2025. https://arxiv.org/abs/2506.06266
Diaz, “Learned Structure in Cartridges: Keys as Shareable Routers in Self-Studied Representations.” 2025. https://arxiv.org/abs/2508.17032
Chari et al., “KV-Distill: Nearly Lossless Learnable Context Compression for LLMs.” 2025. https://arxiv.org/abs/2503.10337
Yuan et al., “Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention.” ACL 2025. https://arxiv.org/abs/2502.11089
Jiang et al., “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models.” 2023. https://arxiv.org/abs/2310.05736
Zhang et al., “H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models.” 2023. https://arxiv.org/abs/2306.14048
Li et al., “SnapKV: LLM Knows What You Are Looking For Before Generation.” 2024. https://arxiv.org/abs/2404.14469
Steele, “On the Limits of Learned Importance Scoring for KV Cache Compression.” 2026. https://arxiv.org/abs/2601.14279
Zhou et al., “EliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection.” 2025. https://arxiv.org/abs/2503.01586
Chen et al., “CodeComp: Structural KV Cache Compression for Agentic Coding.” 2026. https://arxiv.org/abs/2604.10235
Ananthanarayanan et al., “Understanding the Physics of Key-Value Cache Compression for LLMs through Attention Dynamics.” 2026. https://arxiv.org/abs/2603.01426
MiniMax, “MiniMax-M3.” 2026. https://www.minimax.io/blog/minimax-m3
Anthropic, “Using Claude Code: Session Management and the 1M Token Context Window.” 2026. https://claude.com/blog/using-claude-code-session-management-and-1m-context
A key component of LLMs is representing language as a series of high dimensional vectors that include a rich semantic meaning, e.g., cat = [1.23, 3.22, 4.79, 52.72 …].
In brief, a language model’s uncertainty when predicting the next token.
Testing factual recall has been the core of this experimental evaluation, detailed in the last post.
Scores on individual questions varied by about ±1 question across runs.
As I note later, we carry the same limitations as last time for simplicity’s sake, including one coding transcript and using one model small enough to run locally while still running gradient descent.
Pretty much the innovation from the famous paper “Attention Is All You Need” that turned LLMs from gibberish generators into coherent language generators.
For the sake of understanding we’re being really general here. Obligatory video from 3Blue1Brown here if you want to get deeper.
Throughout this post, “3x” means the final number of cache positions is roughly one-third of the uncompressed baseline for the same portion of the transcript . I’m using cache position count as the simple proxy here. This is not an exact end-to-end latency or memory reduction.
This isn’t a regression from Part 4’s results. We never tested 3x sequential in Part 4, only 1.5x and 2x, so the ~5.3/8 is a new data point. Single-turn 3.2x scored 3/3 because the surrounding context was uncompressed; sequential 3x compresses every turn against an already-degraded running cache.
Prefill is essentially the first phase of inference, where the model processes the entire input prompt in a single forward pass, computing attention over all input tokens and filling the KV cache.
Mixture of experts is a fancy way of characterizing an inference cost reduction mechanism that uses a trained model layer to “route” feed forward network calculations to a specific subset of the model. This dramatically reduces the amount of matrix multiplication that’s needed to achieve similar results.
From Ananthanarayanan “Understanding the Physics of Key-Value Cache Compression for LLMs through Attention Dynamics”
See this post for more on how we settled on avoiding key vector modification due to rotational position encoding, or “RoPE.”
It’s impractical even if you had access to more powerful computing than my RTX 5090, my pride and joy.
We arbitrarily chose 300 for this experiment, even though fewer steps might suffice.
“Small” relative to the base model; this would likely be a few hundred million parameters instead of billions.
Beyond what was already covered in the last post.
Steele (2026) trained a 1.7M parameter neural network with multi-horizon lookahead and cross-attention to predict token importance for KV cache compression, and it did not outperform simple heuristics, due to a circular dependence.