
Compressing Coding Agent Context at Models' Native Representation Layer

Introduction & problem
Modern agent/model workflows rely on context (essentially conversation history) to be effective. As context grows1, models “forget” details, slow down, and otherwise display eroded performance, especially as this growing context is compacted2.
Every major coding agent today handles context compression through text summarization (according to public documentation).3 This post builds on past work and explores compressing at the representation level, rather than the text level to see if it’s possible to more-efficiently preserve important details.
Below, we get deep into the details—skip to the practical implications section for conclusions and takeaways.
What we’re tackling
Every time you send a message to an LLM, the entire conversation history gets re-sent as context in the form of English. Coding agents feel this most acutely because their conversations are long (full of tool calls) and the details matter (a wrong file name or path results in broken code). In Part 3 of this series, I discussed how prompt caching (widely used today) reduces compute costs by ~70% by avoiding redundant computation. However, caching doesn’t mitigate the fact that infinitely growing context is difficult to manage and impacts output quality.
Today’s coding agents handle this by truncating old turns, summarizing them into shorter text, or increasing context window size.4 Claude Code, for example, auto-compacts when the context window is nearly full, while Cursor truncates old history. Note that these are text-level interventions—they modify the English conversation before sending it back to the model, while internally representing this information as numerical vectors.
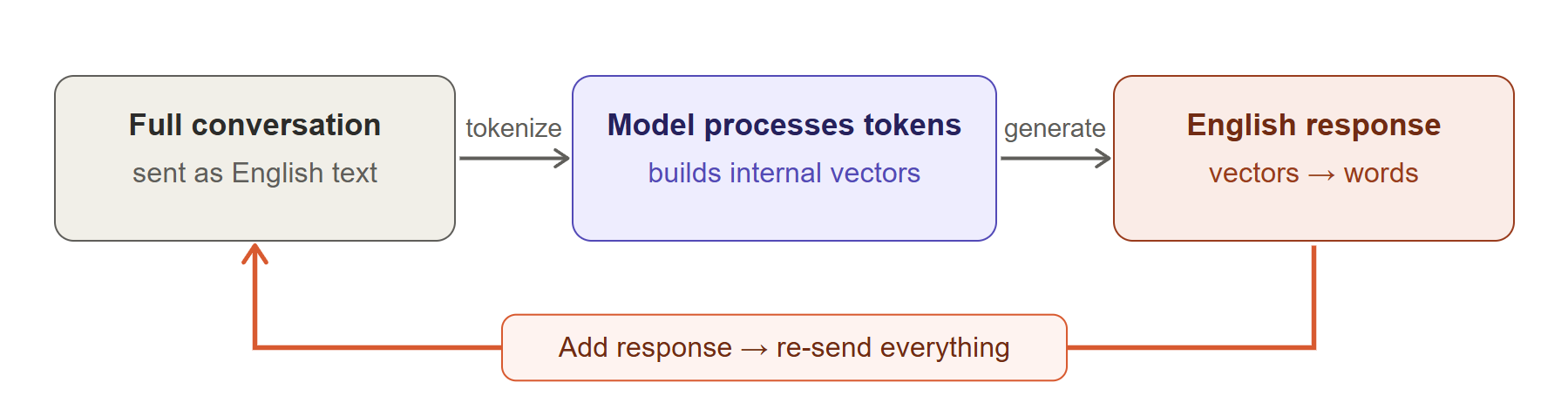
Seeing this made me ask: what if we interacted with internal representations directly?
When a model processes your conversation, it builds representations in the form of numerical vectors5 that encode its understanding of each token in context. When the model generates a response, that understanding gets turned back to English text, and the internal state is discarded6. In the next turn, the model rebuilds everything all over again.
Below, we investigate compressing conversation context into the model’s own representation format. Our experiments compressed a 10-turn coding agent conversation to ~50% of its token count while correctly answering 7 of 8 factual questions about the conversation's content.
What we’re actually doing
When a model reads the text “the project uses bcryptjs for password hashing7,” it creates internal vectors at each of its layers8. These vectors encode important context9 in the human-literal sense—that bcryptjs is a specific npm package and that it’s being used for some security function.
The way we compress is as follows: we create “virtual” tokens, which are new vectors initialized from mean-pooled embeddings10, and we tune them using gradient descent11 until the model’s internal response to them matches its response to the original text. After optimization, these virtual tokens become representations that produce approximately the same internal state when the model processes them as if it had read the full text.
The model itself is frozen, meaning that we’re not training or fine-tuning it. In other words, we’re finding inputs that, when fed through the frozen model, reproduce the internal states that represent the content we want to maintain that are smaller than the original inputs.
How we tested this
The setup
We ran all of the experiments on a local RTX 509012 with 32 GB of VRAM using Qwen 2.5 Coder 7B-Instruct at 8-bit quantization. This particular Qwen model satisfied a few requirements:
We needed a local open-weight model because our technique required gradient access, which API-based models don’t expose.
We couldn’t fill the entire 32 GB VRAM capacity with Qwen parameters because we needed room for gradient computation alongside the loaded model.
The data
We used a (very) generic coding agent transcript recorded from our benchmark in Part 3: a 57-turn conversation where an AI agent builds a task management API with Express and SQLite as an example of a coding workflow. The transcript includes (brief) system prompts, tool calls, file reads, code generation, and debugging.
For single-turn experiments, we worked with a 4,096-token window from this transcript (12 turns). For sequential experiments, we split it into:
Prefix: system prompt
Middle: X turns
Suffix: most recent exchange
The evaluation
We test whether the model can answer factual questions about the conversation using compressed context, measured against full context.
“What library does the project use for password hashing?” (answer:
bcryptjs, not justbcrypt)“What is its
Node.jstest runner?” (answer:node:test, notJest)“Does the markdown converter use a library or
regex?” (answer:regex-based, no external library)
The scoring is keyword-based to keep complexity low, and scores unambiguous and deterministic. This tests whether specific details survive compression and won’t get fooled by plausible-sounding text.
Why this evaluation is useful
Each question has three properties that make it a reasonable test of compression quality:
The answer exists only in the compressed turns: We verify that the system prompt and what I call the suffix (latest input) don’t contain the answer. The model can only get it right by extracting information from the compressed representation.
The model has a wrong “default”: When given no context, the model guesses bcrypt (not bcryptjs), Jest (not node:test), and marked (not regex). These are what I expect are the most popular options from training data. Correct answers require overriding these “defaults” with specific context, which is what our compression methodology needs to preserve.
There are specific ways to be wrong: bcryptjs vs bcrypt is a tiny change and node:test vs Jest is a completely different tool. These are the kind of specific details that text-level summarization (or context compression in general) could easily lose.
The compression recipe that worked
In subsequent sections, I’ve gone into depth on several paths (and dead ends) that led me to a working “recipe” for efficiently compressing context. That recipe is as follows.
Use Value-only optimization targets (vs. Query and Key)
Optimize virtual tokens so their Value vectors (at all layers) approximately match the Value vectors from the full text. This means excluding Keys entirely from the loss (more on this later).
V-vectors carry the actual content that gets processed through attention, the data payload. K-vectors serve as an index—they help the model decide which tokens to attend to. During inference, the model applies RoPE to the virtual tokens’ K vectors at their positions automatically. Since we only optimize V (which is position-independent), we don’t need to worry about positional encoding during the optimization step.
This finding was critical because it circumvents the RoPE problem I hit in Failure 2 below—pooling K vectors from different positions averages together incompatible rotational encodings. There’s been significant work done on KV optimization, and I’ll continue to explore this in future studies. Optimizing V-vectors is simple and more architecture-general.
Use perplexity-weights when V pooling
As in any robust compression, when pooling (i.e., “averaging” or compressing) the V-vectors above into blocks, not all tokens should get equal weight.
We computed per-token perplexity (also known as surprisal or “cross-entropy” when averaged across tokens), which calculates how “surprised” the model was by each token. Boring or “unsurprising” tokens (articles, whitespace) get low weight. Surprising tokens (specific library names, unique identifiers) get high weight.
This weighting mechanism doubled the evaluated compression threshold from 1.6x to 3.2x. This mechanism was a bit unintuitive13—it works by down-weighting “boring” tokens rather than boosting important ones. When predictable tokens carry less weight in the average, the resulting pooled representation is naturally closer to the informative tokens. The optimizing step then has an easier path to matching these improved targets. For example, the loss at 100 virtual tokens dropped from 8.03 to 4.85 compared to uniform pooling in our experiment.
Interpolate positions
Virtual tokens need positions for RoPE on their K vectors during inference. By default, virtual tokens would get consecutive positions (e.g., 144, 145, ..., 218), while the original tokens might occupy different positions (e.g., 146, ..., 385). We spread the virtual tokens’ positions across the original range: torch.linspace(144, 385, 75).
The critical change here is that it preserves the positional distribution that downstream attention expects14 in models. When the suffix (i.e., most important) tokens compute attention, the relative distances to each virtual token approximate the distances to the original tokens. The suffix tokens start at position 386 in our example, regardless of how many virtual tokens there are, acting as if the full middle were present.
The effect is small at low compression (positions are already dense) and more meaningful at high compression, where position clustering would otherwise distort attention patterns.
An important note on practicality
This is a proof of concept—per-instance gradient optimization the way we’ve done it here is too computationally intensive and slow for production use. The path to get it production-ready likely requires training a neural net to predict the compressed virtual token embeddings.
What I tried, what failed, and lessons
To get to the working recipe above, I tried numerous approaches and hit several hurdles. Below is a map of that path and how each failed test narrowed the design space that led to the results.
Note that when I’m discussing “loss” below, I’m referring to mean-squared error between two sets of vectors that gradient descent is minimizing. The two sets in this case were virtual tokens and the real tokens they were attempting to represent.
Failure 1: Optimizing for final layer is the wrong objective
My first approach was to create virtual tokens and optimize them so that the model’s output at the final layer matches what the real tokens produce. Using this method, it looked like the virtual tokens were producing “correct” final representations.
However, in testing, our eval answers looked like there was no context at all, and the model was “guessing” its training defaults.
The lesson: When the model generates text, it isn’t solely reliant on its final layer15. At every layer independently, each generated token attends to the KV cache entries from previous tokens. This means that optimizing only for the final layer results in significant loss in previous layers.
Failure 2: Including Keys in optimization difficult due to RoPE
In my next attempt, I switched to optimizing the KV entries at all 28 layers. I noticed that loss declined (and later significantly plateaued), but the eval answers were still often wrong.
The problem: Modern models apply position-dependent rotations to Key vectors, which is called Rotary Position Embeddings, or RoPE. The purpose of RoPE is to encode token positions in a way such that when the model calculates attention, it naturally takes into account relative positions between each token. When we start pooling K vectors from various positions, however, we start averaging vectors with different rotational encodings. The result is a rotational mess that no single-position virtual token can match.
I also confirmed that RoPE isn’t unique to Qwen models, and is used by LLaMA, Gemma, and virtually every modern open-weight model. Any compression approach that targets K vectors will hit this wall.
The lesson: RoPE makes K vectors position-dependent, but Value vectors are position-independent. We verified in Qwen’s source: query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin). This means we can modify and optimize V without worrying about positional encoding.
There’s room for improvement here since RoPE rotations are deterministic and reversible, a future approach could undo the rotation, optimize K pre-RoPE, then re-apply it for inference
Failure 3: Attention-weighted pooling is both question-specific and regresses results
Once V-only optimization was working, I tried improving the pooling targets (it’s something we’ll have to come back to in future work). Instead of giving all V vectors equal weight when averaging them into blocks, I tried weighting them by how much the evaluation question’s tokens attended to each position. The thought was: high-attention tokens should be preserved better, right?
It’s important to note, though, that this was a rudimentary approach chosen for simplicity given the risk of “overfitting.” The results actually got worse. 150 tokens went from 3/3 to 2/3 correct answers.
The lesson: Attention-weighted pooling is inherently question-specific. Weighting toward one question’s attention pattern down-weights tokens that other questions need. There may be better weighting mechanisms for query-agnostic compression that we can explore in the future.
An aside on the helpfulness of AI
It goes without saying that AI coding agents were integral in running these experiments. Of course, AI was vital in writing the necessary Python code to create and run the tests. What I didn’t expect, though, was how I used it to help me run feasibility tests to avoid hitting unnecessary obstacles. For example:
Mr. AI, please help me figure out which Qwen model to use so I don’t overflow to system DRAM if I have to run gradient descent on my loaded model and therefore have it take days to run.
Results Summary

3.2x preserved all tested facts for all three turns. Larger turns compress equally well. Turn 24 has the lowest optimization loss at every ratio, suggesting more tokens give the optimizer more material to work with.
At 4.8x, failures follow a similar pattern of degrading names or strings:
“
bcryptjs” → “bcrypt” (dropped the JS suffix)“
dev-secret” → “dev-dev-dev-dev-dev...” (strange repetition of the prefix)“
done” → “completed” (fell back to a training synonym)
Structural facts seem to survive much longer than exact names. For instance, the model knows which library is used for password hashing well past the point where it “forgets” the exact name of that library.
Sequential multi-turn: 2x preserves most facts across 10 turns
Single-turn compression gives us a great signal on the compression mechanism we tested, but coding agents rely on long, multi-turn conversations. The next step was testing sequential compression: compressing each turn independently and building up a running KV cache.
Sequential Compression in practice

Sequential Compression Results
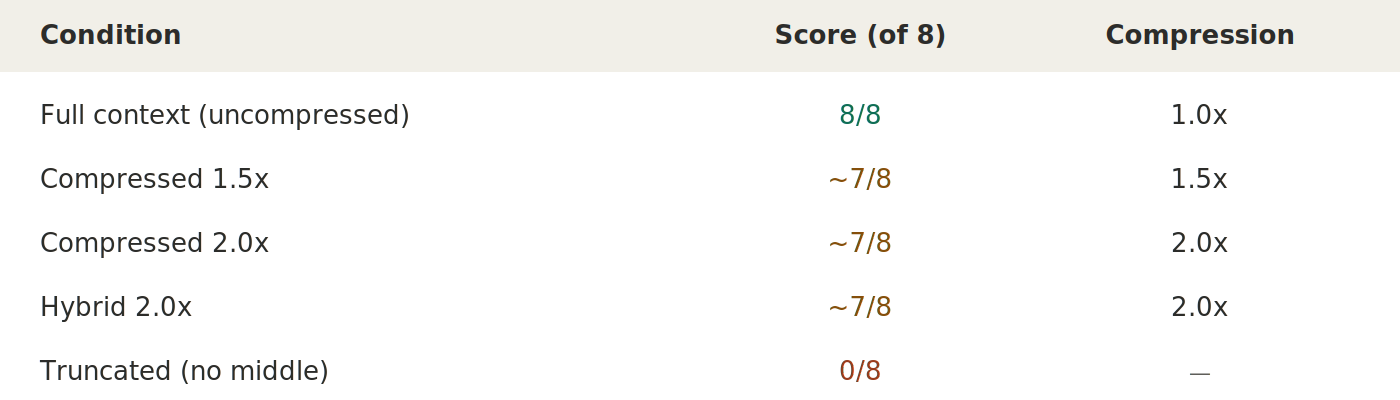
The main finding was that there is minimal error accumulation across turns: meaning the optimization process works equally well at each step. The remaining question, whether the targets themselves drift as compressed context accumulates, is harder to measure directly in this set of experiments. That said, the fact that 2x compression still preserves 7 of 8 answers suggests this drift (if it exists) remains bounded.
Practical Implications and final thoughts
Getting deep into manipulating internal representations to optimize coding agents, as we’ve done here, can help us gain an intuitive and applicable understanding of several concepts and model behaviors. Taking that understanding and applying it to real user problems reveals insights that can help us shape how we might build the coding agents of tomorrow.
In these experiments, we’ve learned that categorical facts like ‘the project uses JWT for authentication’ survive high compression, while exact names like bcryptjs degenerate to the model’s “defaults,” bcrypt, under high compression. Despite the challenge, we’ve also learned that there’s significant headroom for more context efficiency in coding agents. Making such improvements would solve several key issues with coding agents as they exist today, and might make them more useful broadly. Applying the above, I would combine several approaches to create a personalized and efficient context strategy.
Compression: Compress context at the representation level with V-vector optimization, using perplexity to weight V-pooling and interpolate virtual tokens. Our proof of concept shows that it may be possible to compress context ~3x using this method. This is also complementary to caching–combining compression with prompt caching could add significant additional savings. Of course, the next step would be building a model to productionize what we’ve learned.
Systematic Preservation of Vital Information: Preserve vital information and keep it verbatim (more to follow on how best to do this in future work). Simple file systems and knowledge graphs using markdown files seem to be the most popular approach. It may also make sense to preserve important information from these file reads in a context window verbatim. This is where personalization comes into play—what type of “memory” system someone uses and what serves as useful information outside of interacting with an agent differs from person to person. This is also complementary to compression.
Intelligent Compaction: We’ve discussed before that Anthropic moved away16 from exposing very long (1M token+) context windows by default given the intrinsic issues. With the above techniques at our disposal, we could be more intelligent about when we compress instead of waiting for a certain context window threshold.
I would love to explore using signals to automatically trigger compaction and disposal of context, or encourage users to provide those signals directly. Examples include: forking conversations, discarding the last turn if it had a poor result, and having a meta conversation that preserves specific context. This same principle also applies to sub-agents—deciding explicitly whether sub-agents should have context (and what context), and where they should write outputs.
In today’s landscape, a lot of the burden of context management (and even understanding the problem) is put on the user. We could abstract this into the model harness itself, powered by new techniques.
Future work
There are several directions I want to explore from here.
Optimizing K vectors pre-RoPE: We circumvented the RoPE problem entirely by only optimizing V, but since RoPE rotations are reversible, we could undo them, optimize K directly, then re-apply them. This could push the compression threshold beyond 3.2x by jointly optimizing both.
Re-testing the hybrid approach by preserving specific pieces of context verbatim and compressing the rest, at the representation level.
Combining embedding compression with KV cache eviction: Our technique preserves historical context in approximate form. Published eviction methods like H2O and SnapKV manage the growing current context by dropping low-attention entries entirely, and these efforts would be complementary.
Testing the sub-agent context architecture ideas above: The compression research tells us what’s possible with context efficiency, and it would be interesting to apply that systematically to sub agents from a product perspective. For example, what context sub-agents receive, whether it should be compressed or verbatim, and when to discard context entirely.
Appendix
Limitations
There are several limitations to note.
Model choice and scale: All of the experiments were conducted using Qwen 2.5 Coder 7B. Larger models with more attention heads and parameters might behave and perform differently. On one hand they might have higher representational capacity in each virtual token. On the other, there are more complex internal representations for a virtual token to approximate. We were hardware bound, but I’d love to test the same mechanisms in more capable models.
Eval / benchmark simplicity: We used a single transcript with a set of binary evaluation questions for simplicity. In previous experiments, broken pipelines (and things as simple computer sleep) resulted in numerous restarts, leading me to focus on the simplest option possible for this phase of research. The compression threshold and degradation patterns need validation across different codebases, programming languages, and types of conversations.
Sequential test oddities: Even 1.5x compression scores ~7/8 on the sequential experiment we ran, suggesting that the sequential pipeline has some quality loss likely beyond what compression ratio alone explains. It’s just something to be explored further.
Hybrid approach is difficult to validate on short contexts: On short turns (e.g., 240 tokens), preserving ~15% of them consumes too much of the “compression budget” and results in a compression ratio that’s too aggressive.
An initial look at a hybrid compression approach
In the above experiments, failures at 4.8x compression are always specific tokens whose signal gets diluted during pooling. Applying a text-level compression technique I’ve attempted before, what if we kept those tokens verbatim and only compressed the rest?
The biggest challenge here was identifying which tokens to exempt. We tested two signals:
Perplexity: Represents how “surprising” the token was. Unfortunately, this selects formatting markers and sub-word fragments as well as useful ones. Sometimes, tokens that are surprising carry no useful content (hence we down-weighted low perplexity tokens in our pooling methodology). More broadly, perplexity wasn’t a useful signal (at least when applied this way) at the macro-content level, even though it was useful for pooling.
“Uniqueness” of V: Represents how different a token’s internal representation is from its neighbors. This selects content words like Task, converter, reports, SQLite, authenticate, userId. These are exactly the tokens that lose the most from being averaged with their neighbors during pooling.
Using this technique, we saved the top 15% of tokens by the uniqueness of V, and their KV entries passed through the pipeline unmodified at their original positions (with correct RoPE). Then, we compress the remaining 85%.
Bibliography & Related Work
Our main technique, embedding optimization (without pre-training), builds directly on Kuratov et al.’s work demonstrating that hundreds of tokens can be compressed into optimized embedding vectors (Cramming 1568 Tokens into a Single Vector, ACL 2025). We apply their technique to multi-turn coding agent conversations and add the V-only optimization target, perplexity-weighted pooling, and sequential turn-by-turn compression.
The KV cache compression research field is quite active. Most approaches compress the cache after computation through quantization or eviction. Our approach is different in that we optimize input embeddings beforehand. Notable work in this space includes EliteKV (RoPE frequency selection), CodeComp (structural compression for coding agents).
KV cache eviction methods like H2O and SnapKV manage growing context by dropping low-attention entries entirely. I would expect these to be complementary to our approach, since compression preserves important historical context, and eviction manages the current context’s memory footprint.
LLMLingua (Jiang et al., 2023) uses perplexity to discard tokens at the text level. We use perplexity to weight V-vector pooling at the embedding level, which is the same signal applied at a different level of the model.
Anthropic’s guidance on session management and context rot informed our experimental motivation and how widespread this problem is.
Bibliography
Kuratov et al., “Cramming 1568 Tokens into a Single Vector and Back Again: Exploring the Limits of Embedding Space Capacity” ACL 2025. arxiv.org/abs/2502.13063
Jiang et al., “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models.” 2023. arxiv.org/abs/2310.05736
Zhang et al., "H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models." 2023. arxiv.org/abs/2306.14048
Li et al., “SnapKV: LLM Knows What You Are Looking For Before Generation.” 2024. arxiv.org/abs/2404.14469
Zhou et al., "EliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection." 2025. arxiv.org/abs/2503.01586
Chen et al., "CodeComp: Structural KV Cache Compression for Agentic Coding." 2026. arxiv.org/abs/2604.10235
Anthropic, “Using Claude Code: Session Management and the 1M Token Context Window.” April 2026. claude.com/blog/using-claude-code-session-management-and-1m-context
This means the model uses some summarization technique to “compact” context into something more manageable to keep working.
Codex calls an API that is opaque to the public.
Compounded further by increased use of agents.
Essentially using coordinates in a high-dimensional space (e.g., [1, 3.2, 4, 7] = cat) to represent pretty much anything.
It’s not quite discarded in the case of caching, but for purposes of this particular point, the message holds.
We’re focused on coding tasks, since that’s the use case where a lot of this pain is felt, though it’s likely broadly applicable outside of coding.
Qwen 2.5 coder 7B has 28 model layers.
A while ago, it took me a long time to figure out how attention works—it’s the mechanism that’s the core of modern LLM architecture. To put it in a few words, attention allows a model to understand whether “go” seen in input is a command, a turn (in the British sense), an ancient board game, who is going, and so on. This video captures it far better than I could explain in text.
It’s pretty much a fancy way of saying averaging together a bunch of vectors.
I’m very proud to note that I’m now getting non-gaming use out of this expensive graphics card that I spent multiple months trying to acquire at MSRP.
This is because the important tokens (to us) don’t necessarily have high perplexity. Yet, we’re able to reduce the dilutive impact of unimportant ones.
If all the virtual tokens were packed into consecutive positions, the model would lose valuable information on relative positions of tokens that it expects (that we’ve now messed with). The interpolation we’ve done across the original range gets us to “good enough.”
To be honest, I excitedly rushed through this step and didn’t fully think through my optimization. Nevertheless, it was a neat way to empirically show how wrong I was.
At least as it was noted several weeks ago.