
Why I stopped copy-pasting between Claude windows (and what I did instead)

AI is better at writing prompts for AI than humans are (for the purpose of writing code).
Or at least that’s what it has felt like as of late. I’ve recently fallen into a pattern of copying and pasting generated prompts between multiple Claude Code and Claude windows (embarrassing – I know), and getting much better results than I would have otherwise.
What started as an attempt to optimize my workflow led me down a rabbit hole to improve model + harness performance and trying to address longstanding issues with context window length. Namely that compaction is lossy and token-inefficient.
Here’s the long and short of what I learned:
The Research
Models “attend” (pay attention) worse to mid-context information (it’s improved but not solved)
AI-generated prompts (might) outperform human ones on complex tasks
The latter should be taken with a grain of salt, but at the very least might help reduce the amount of time it takes to translate human intent into an output or outcome.
The Approach
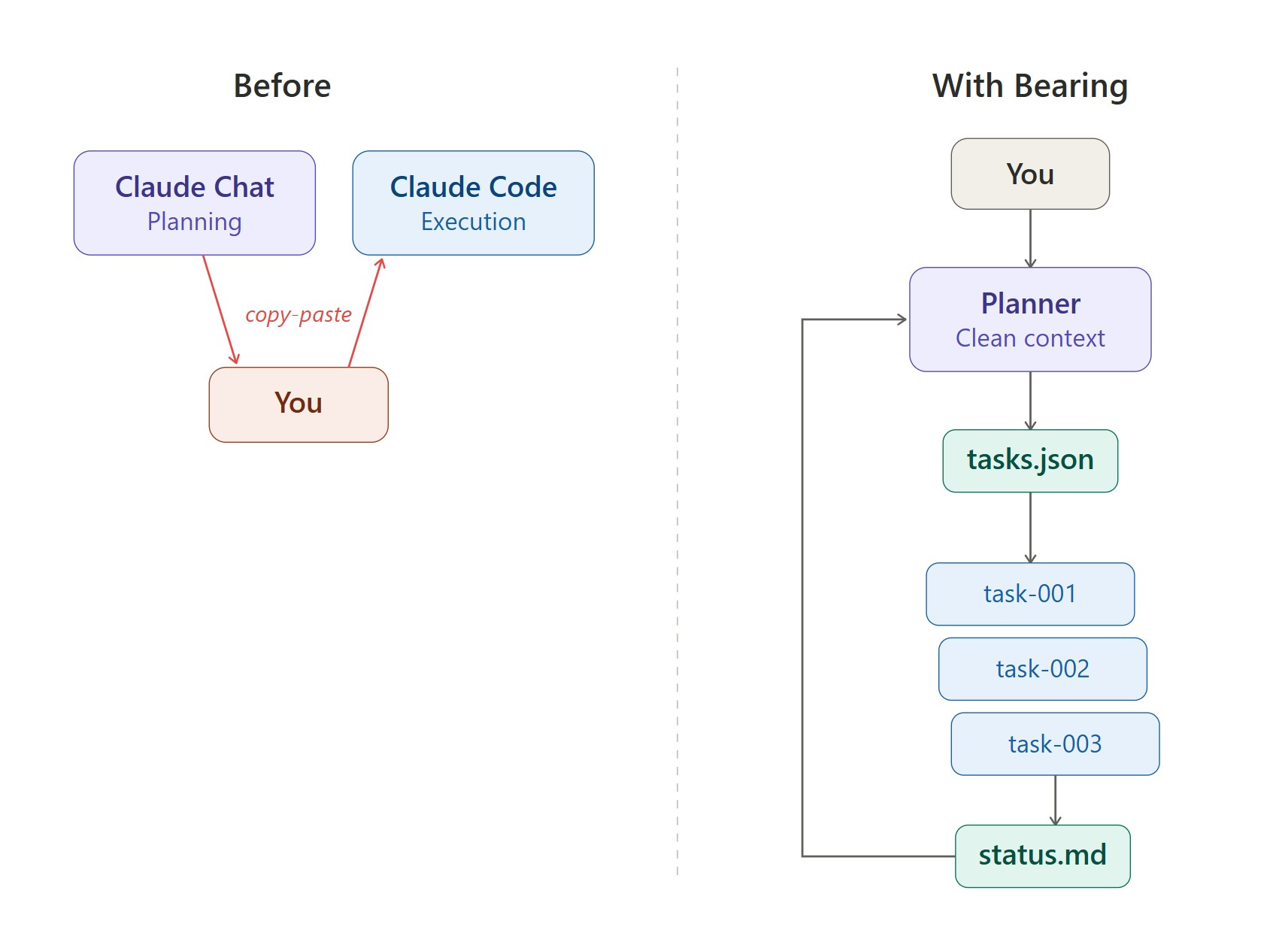
Separate planning from execution context windows to keep both clean
Assist AI compaction to preserve relevant context, especially for long-running tasks
Keep the human in the planning loop to better achieve what you intend
These are all implemented in Bearing, an open-source tool that separates planning from execution across AI coding agents.
Early Results
In a long session, compaction can discard the vast majority of your conversation history. In one of my sessions, 99.5% was dropped, keeping decisions but losing the reasoning behind them. Bearing avoids this on the execution side entirely: each task starts with a fresh context window
The Attention Problem
In 2023, Stanford and Meta researchers (Liu et al., 2024) documented the “Lost in the Middle” phenomenon: model performance follows a U-shaped curve, highest when relevant information is at the beginning or end of the context, degrading when it’s buried in the middle. GPT-3.5’s (yes that’s an old one, as are some of the ones below) accuracy dropped over 20% when key information sat mid-context.
Newer models, of course, have improved dramatically on this. As early as 2023, Anthropic showed that a simple prompt adjustment raised Claude 2.1’s retrieval accuracy from 27% to 98% across its 200K context window (Anthropic).
Despite these improvements, 2026 best-practice guides still recommend placing critical information at the beginning and end of context windows. This practical problem persists in a different form: even if the model can technically attend to everything, a Claude Code session that’s accumulated five tasks worth of test output, and error traces has a much noisier context than a fresh session with just the task prompt. The signal-to-noise ratio degrades regardless of whether the model’s “positional attention” is uniform.
In other words: your intent from attempt 1 isn’t lost because the model can’t read the middle of its context. It’s lost because it’s competing for attention with dozens of other signals that have accumulated since then.
Why AI should (maybe) write prompts for AI
When you tell Claude Code “add dark mode,” your brain fills in 20 things you don’t say: where the toggle goes and what it looks like, how to persist the preference, how to contrast with the existing color scheme, and more. It’s difficult to figure out which details to fill in, and which an agent might fill in better than you might plan—worse, it’s tough to know what might anchor an agent on a suboptimal path.
This can be especially tough because an executing coding agent starts without much shared context (except what you painstakingly provide in markdown files, of course).
An AI planner writing a prompt for the executor doesn’t assume shared context — it knows the target session is clean. It specifies which files to read, what approach to take, what to verify when done.
There may be some reasons attributable to training that show why this works. Google DeepMind (Yang et al., 2023) and Microsoft Research have both shown AI-optimized prompts outperforming human-written ones on benchmarks (OPRO, PromptAgent), though how directly this applies to coding agent prompts is still an open question. Models were optimized during RLHF against structured, complete instructions. An AI writing a prompt for another AI naturally produces text in that format.
There’s an added layer to all of this: as the world stands today, I believe that human + AI interaction can serve as a more effective planner in translating intent into outcomes than either alone. Many people writing about vibe coding have played with markdown files and prompt generation to make a coding agent one-shot most (easy) tasks quite effectively. That said, as tasks grow in complexity, this approach has its limits. Together, a human can bring taste, judgment, and domain knowledge, while the AI brings completeness, structure, and format the executor is optimized for.
Doesn’t Claude Code Already Do This?
Kind of. Claude Code already separates planning from execution. Plan mode creates a plan before writing code, subagents create workers, and agent teams have a lead that coordinates agents.
As far as I’ve seen though, the planner is the AI talking to itself. Plan mode plans, then executes with the same context window and without human input during the planning phase. Agent Teams have a lead, but that lead makes architectural decisions autonomously.
Claude Code’s plan mode likely won’t say “wait – we’re not thinking about [insert vital topic here]” It won’t say “actually, build the database layer first because everything depends on it” unless you thought to ask. It can’t bring your product instinct into the architectural conversation because it doesn’t have access to it.
The issue also isn’t planning versus execution. Given the way typical workflows are currently structured, it’s whether the human is in the planning loop or downstream of it.
What does Bearing do then?
I built a tool called Bearing to test these ideas. Here’s how it works:
You open an interactive Claude Code session; that’s your planner (running Opus or another performant model) that’s focused on strategy. You have a real conversation to do anything from debating architecture to pushing back on complexity, and making decisions.
When you converge on a direction, the planner writes a structured task file. Each task specifies the CLI tool, model, budget, turn limit, which files are relevant, and a detailed prompt drawn from your conversation.
Then you run
bearing run .and each task executes in a new, isolatedclaude -psession.Results write back to a status file – the planner reads the results. You discuss what to adjust, and the cycle continues.

A couple benefits of this approach:
Model-agnostic execution: Each task specifies which CLI runs it — Claude Code, Codex, or any custom agent. You can also mix them in the same task queue.
Context focusing: Instead of the executor reading your entire codebase and hoping attention lands in the right place, each task specifies which files matter and which to skip. The executor sees FOCUS: Read these files first and SKIP: Do not read or modify these before the task prompt. This reduces token consumption and concentrates the model’s attention on relevant code. Quick note here – I’m working on a better approach that I’ll write a bit about next time.
Auto-context propagation. When task-001 completes, its summary and file list automatically inject into every dependent task. That means task-002 knows what task-001 created without the human manually copying context between sessions.
This also means no more copying and pasting between chats, which is how this whole thing started, and AI handles the translation from intent to implementation.
The Deeper Problem: Context Compression
There’s a larger issue beneath all of this that hasn’t been solved (or even addressed, really) yet.
When a context window compacts, whether through Claude’s built-in summarization or simply through the model attending less to older content, information loss is unstructured – the model isn’t great at knowing what you consider important. Some big architecture decision from prompt 3 could get the same treatment as a debug trace from prompt 17 (most of you have probably seen a typical Claude memory reference to something entirely irrelevant – this is similar).
The planner layer offers a structural answer to this. Because the planner curates what context flows into each task — which files matter, what previous tasks accomplished, what the human decided and why — it’s performing a form of (slightly) intelligent compression that the model doesn’t do on its own.
It’s important to note that this attempt is quite early. The current implementation uses text summaries and file lists. A more ambitious version might generate structured relevance maps, prioritize context by impact, and compress differently for different task types, and that’s only one potential approach. It’s also possible or even likely that Anthropic and OpenAI will build some of this into their tools natively.
Regardless, I might contend though that a human-in-the-loop planning layer can make better context decisions than a model alone, at least in the current era of LLM-based agents.
Try It
git clone https://github.com/rocketvish/bearing.git
cd bearing
uv tool install -e .
cd <your-project-directory>
bearing start .This is open source and has no dependencies. The repo includes examples and a planner prompt that teaches your AI session how to write task files.
The code is at github.com/rocketvish/bearing. I’d love to hear what works and what doesn’t.
Final Thoughts
The aforementioned rabbit hole turns out to be deeper than I imagined. Context compression has always been lossy, and as far as I know, no one is solving it structurally yet. Bearing is a rudimentary attempt. If you’ve hit the same wall — your agent forgets what matters three tasks in — I’d love to hear how you’re solving it.
Appendix
How this differs from the Landscape
The current ecosystem is focused on parallelism, running more agents simultaneously:
Garry Tan’s gstack (github) assigns different personas to a single Claude Code session via 23 slash commands, but it’s still one context window accumulating everything.
Steve Yegge’s Gas Town (github) runs 20-30 parallel agents coordinated by a Mayor agent, with Polecats for execution, a Refinery for merge queues, and persistent state in Git via Beads. Architecturally ambitious — it’s designed for massive parallelization across large codebases.
Anthropic’s Agent Teams (docs) is Claude Code’s built-in multi-agent feature. One session acts as team lead, coordinating teammates that each get their own context window.
Conductor (Melty Labs) is a YC-backed Mac app that gives you a visual UI for parallel Claude Code agents. If you want to run 5 agents on different features simultaneously, Conductor is excellent.
What all of these share: they solve the problem of running more agents in parallel, coordinating their work, and managing conflicts, generally scaling throughput.
What none of them address: the planning conversation. The back-and-forth between human and AI where you debate architecture, challenge complexity, make strategic decisions, and translate vague intent into precise tasks. In every tool above, the planning either happens in the same polluted context as execution (gstack), or is done autonomously by an AI lead without human input (Agent Teams, Gas Town), or isn’t part of the tool’s scope at all (Conductor).
Bearing doesn’t compete with these tools. You could use Bearing for planning and Conductor for parallel execution. The question Bearing answers is “how do I think clearly about what to build while AI builds it?”
Sources:
Liu et al., “Lost in the Middle: How Language Models Use Long Contexts” (TACL, 2024) — tested on GPT-3.5 and Claude 1.3; the positional attention effect has been reduced in newer models but the signal-to-noise principle still holds
He et al., “Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding” (2024) — proposes Ms-PoE to mitigate the lost-in-the-middle effect
Yang et al., “Large Language Models as Optimizers” (OPRO) (Google DeepMind, 2023)
Wang et al., “PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization” (2024)
Microsoft Research, “PromptWizard” (2025)
Ouyang et al., “Training language models to follow instructions with human feedback” (InstructGPT) (OpenAI, 2022)
Bai et al., “Training a Helpful and Harmless Assistant with RLHF” (Anthropic, 2022)
Addy Osmani, “The Code Agent Orchestra” (2026) — comprehensive overview of multi-agent coding patterns
Maggie Appleton, “Gas Town’s Agent Patterns, Design Bottlenecks, and Vibecoding at Scale” (2026)